
RedPajama, which creates fully open-source large language models, has released a 1.2 trillion token dataset following the LLaMA recipe.

RAG Is A Hack - with Jerry Liu from LlamaIndex – Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and all things Software 3.0

Timeline of computing 2020–present - Wikipedia
今日気になったAI系のニュース【23/4/24】|shanda

RedPajama-Data-v2: an Open Dataset with 30 Trillion Tokens for Training Large Language Models : r/LocalLLaMA

RedPajama 7B now available, instruct model outperforms all open 7B models on HELM benchmarks
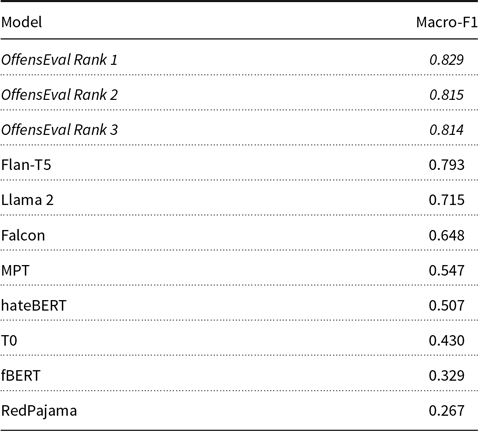
OffensEval 2023: Offensive language identification in the age of Large Language Models, Natural Language Engineering
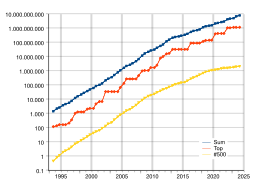
Timeline of computing 2020–present - Wikipedia

LLaMA clone: RedPajama – first open-source decentralized AI with open dataset

Open-Source LLM Explained: A Beginner's Journey Through Large Language Models, by ByFintech @ AI4Finance Foundation

Preparing for the era of 32K context: Early learnings and explorations

Why LLaMA-2 is such a Big Deal

2023 in science - Wikipedia






